GEOPY
Menu Principal
MEIE2
Métodos
de Inferencia Estadística con dos poblaciones
Una de la situaciones
más frecuentes en inferencia estadística tiene
lugar cuando se comparan dos grupos de individuos o grupos
experimentales en cuyos individuos ha sido definida una variable
aleatoria con distribución normal. Asumiremos que el grupo 1
es aquel cuyos individuos son sometidos a un tratamiento 1, mientras
que el grupo 2 es el grupo control o grupo de individuos sin
tratamiento; o el grupo 1 recibe un tratamiento 1 y el grupo
2 un tratamiento 2. El tratamiento puede un medicamento, abono,
aplicación de un compuesto químico etc.; o un
factor biótico como la pertenencia a un grupo social, sexo,
presencia de un gen; o cualquier factor abiótico como por
ejemplo la ubicación geográfica, clima,
temperatura etc. En esta clase de situación experimental el
modelo estadístico asume que un tratamiento
tendrá un efecto si aumenta o disminuye el valor medio de la
variable en un grupo experimental, considerándose este
aumento o disminución con respecto a la media del otro grupo
experimental.
[
Definiciones, conceptos y
métodos]
-
Explicación del script
De forma similar a la inferencia
estadística con una población, en la inferencia
estadística con dos poblaciones un paso previo consiste en
la realización de un análisis de
estadística descriptiva con los datos experimentales de cada
muestra (líneas 26 y 40), obteniéndose
además distintas clases de gráficos que nos
ayudarán en la interpretación de los resultados.
En el script se muestra el código que permite obtener con
los datos de las dos muestras su correspondiente diagrama de
dispersión, gráfico de caja y bigotes,
gráfico de probabilidad normal, histograma e histograma
gaussiano (líneas 42-
Si efectivamente se cumple el supuesto de normalidad de la variable
entonces se estará en condiciones de realizar el contraste
de medias poblacionales aplicando pruebas paramétricas, por
ejemplo el t-
El t-
s.ttest_ind(col1,
col2)
o si son
distintas,
escribiéndose (línea
138):
s.ttest_ind(col1, col2, equal_var=False)
En la
línea 143 se ha
fijado un valor del nivel de significación del 5%, valor que
debe ser cambiado en función del riesgo que conlleve aceptar
la H0. Entre las líneas 140 y 153 se aplica la regla de
decisión, en las dos situaciones con respecto a las
varianzas poblacionales.
Finalmente,
se muestra el
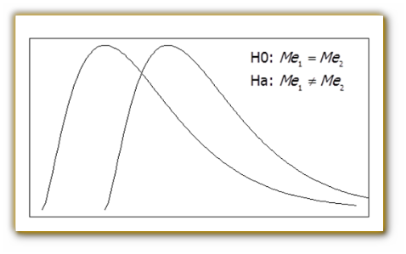
código que realiza el test de la U de Mann Whitney
(líneas 154-
A
continuación, entre
las líneas 88 y 114 se efectúan los tests de
normalidad con los datos de cada muestra: test de Kolmogorov-
La prueba se
realiza con al
función:
s.mannwhitneyu(col1,col2)
fijándose el valor del nivel de significación
igual a 0.05 en la línea 157. La regla de
decisión se muestra entre las líneas 156 y 161.
Laboratorio
____________________________________________________________________________________________
-
Comparación del caudal de un rio en dos estaciones
En un estudio se desea comparar
el caudal máximo anual del Rio James (Virginia, EE.UU.)
medido en dos épocas diferentes. ¿Qué
estadístico utilizaremos? ¿por qué?
¿Qué concluimos en este estudio?
Solución: ejemplo41.mp4